
Neural-Control Family: What Deep Learning + Control Enables in the Real World
With the unprecedented advances of modern machine learning comes the tantalizing possibility of smart data-driven autonomous systems across a broad range of real-world settings. However, is machine learning (especially deep learning) really ready to be deployed in safety-critical systems?
While visiting Caltech, an aerospace director said:
I would love to incorporate deep learning into the design, manufacturing, and operations of our aircraft. But I need some guarantees.
Such a concern is definitely not unfounded, because the aerospace industry has spent over 60 years making the airplane safer and safer such that the modern airplane is one of the safest transportation methods. In a recent talk “Can We Really Use Machine Learning in Safety-Critical Systems?” at UCLA IPAM, Prof. Richard Murray discussed the number of deaths from transportation every $10^9$ miles in the U.S.:
| Human-driven car | Buses and trains | Airplane | Self-driving car |
| 7 | 0.1-0.4 | 0.07 | ? |
Based on this analysis, if I travel from LA to San Francisco, on average, taking a flight is 100 times safer than driving myself (also faster). Moreover, the above table is begging the following question: For deep-learning-based autonomous systems, how do we ensure a comparable level of safety to human or classic methods while maintaining advantages from deep learning?
To make progress on this challenge, I would like to present a class of learning-based control methods called Neural-Control Family, where deep-learning-based autonomous systems not only achieve exciting new capabilities and better performance than classic methods but also enjoy formal guarantees for safety and robustness. Here are some demonstrations, where all robots are running deep neural networks onboard in real-time:

|
| Neural-Lander |

|
| Neural-Swarm |

|
| Neural-Fly |
These novel capabilities are very exciting because they haven’t been achieved by either pure learning or control methods. For example, the close-proximity swarm flight (the minimum distance is only 24cm) in Neural-Swarm, and agile and precise maneuver in time-variant wind conditions in Neural-Fly. Behind these “magics”, in this blog, I will try to explain the methodology, and in particular, I aim to discuss three key principles when applying deep learning in autonomous systems:
- Having prior physics matters.
- Control meets learning: combining learning and control theory is necessary.
- Encoding invariance to deep learning really helps.
Having prior physics matters
A real-world dynamical system can be described as
\[x_{t+1} = \underbrace{f(x_t,u_t)}_{\text{nominal dynamics}} + \underbrace{g_t}_{\text{residual dynamics}} + \underbrace{w_t}_{\text{disturbance}},\]where $x$ is the state and $u$ is the control input. Most importantly, the nominal dynamics $f$ refers to the easy-to-model part from prior physics, while the residual dynamics $g_t$ (potentially time-variant) refers to the hard-to-model part. As shown in the following image, in different systems $g_t$ could have different structures.
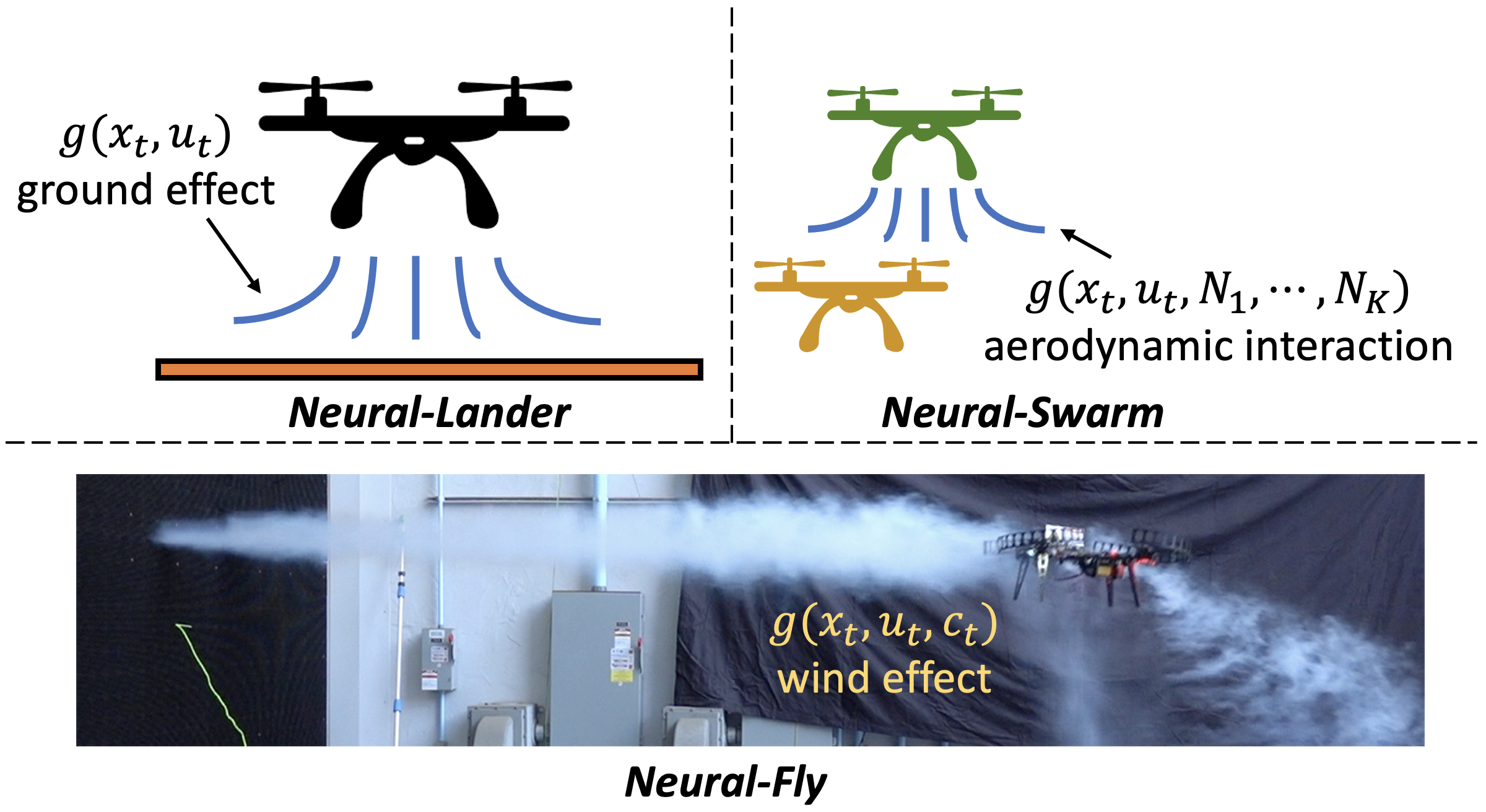
|
For example, in Neural-Lander, $f$ is the classic rigid body dynamics for a drone flying in the free space, and $f$ could be easily modeled by standard bench tests. However, $g_t=g(x_t,u_t)$ is the complex aerodynamic effect between the drone and the ground, which is nonlinear, nonstationary, and very hard to model using standard system identification approaches.
In Neural-Swarm, the residual dynamics is more involved, because it also depends on the drone’s neighbors: $g_t=g(x_t,u_t,N_1,\cdots,N_K)$, where $N_k$ is a set of the type-$k$ neighbors. More specifically, $g_t$ is the aerodynamic interaction between different types of robots in a swarm. In Neural-Fly, the residual part depends on the unknown wind condition $c_t$: $g_t=g(x_t,u_t,c_t)$. External wind conditions have a significant influence on the drone dynamics, as visualized in the above image (a drone flying in Caltech Real Weather Wind Tunnel).
Since the nominal dynamics $f$ is highly structured and easy to model using classic approaches, there is no reason to use deep learning to model it. The high-level idea of the Neural-Control Family is, we use some deep learning methods to model the residual dynamics $g_t$, and then leverage the structure in the prior physics to design a hybrid controller:
\[u_t = \underbrace{\pi_n(x_t)}_{\text{nominal controller}} + \underbrace{\pi_l(x_t,\hat{g}_t)}_{\text{learning-based controller}},\]where $\hat{g}_t$ is the estimation of $g_t$ from some machine learning method. Here, I want to point out that having prior physics is crucial for two reasons:
- The form of $\pi_n$ and $\pi_l$ highly relies on the structure in the prior physics. It is also why we can translate the learning performance (i.e., how close is $\hat{g}_t$ to $g_t$) to the control performance in the following section.
- From both computational and statistical standpoints, having prior physics significantly makes the learning algorithm more efficient. For instance, in Neural-Lander, we found that to achieve the same training loss, learning the full dynamics $f+g$ requires 1 hour of flight data while learning the residual dynamics $g$ only needs 5 minutes!
Control meets learning: combining learning and control theory is necessary
The second important principle is that, to safely deploy deep learning in autonomous systems, it is necessary to study learning and control theory in a unified framework. More concretely, deep learning is more or less like a powerful yet obscure blackbox, so we must regularize and verify its behavior in high-stakes problems.
In Neural-Lander, we use a deep neural network $\hat{g}(x_t,u_t)$ to approximate the residual dynamics $g$. We proved that if the Lipschitz constant of the DNN is smaller than some system-dependent threshold $\gamma$, the learning-based controller is exponentially stable (i.e., the trajectory tracking error exponentially converges to some small error ball whose size is related to the learning performance). Recall that for a function $h(z)$, the Lipschitz constant $L(h)$ is defined as the smallest value such that \(\forall z,z',\|h(z)-h(z')\|/\|z-z'\| \leq L(h).\)
Basically, the Lipschitz threshold $L(\hat{g}) \leq \gamma$ requires some global smoothness property of the DNN $\hat{g}$. Note that this constraint is from control theory (i.e., we must jointly consider learning and control theory to have such a result), and necessary! Actually, modern DNN training itself is far away from satisfying $L(\hat{g}) \leq \gamma$: for our drone systems, $\gamma\approx16$, but an 8-layer DNN without Lipschitz constrained training yields $L(\hat{g}) > 8000$, which led to a drone crash in our experiments. In practice, we use spectral normalization to ensure that $L(\hat{g}) \leq 16$. With the spectrally normalized DNN, we can achieve the following agile maneuver super close to the ground:

|
Another example to unify learning and control theory is in Neural-Fly, where we propose a new framework called Meta-Adaptive Control. Recall that in Neural-Fly the residual dynamics $g(x_t,u_t,c_t)$ depends on the environmental condition $c_t$. The idea is that we decompose $g$ into two parts:
\[g(x_t,u_t,c_t) \approx \phi(x_t,u_t) a(c_t),\]where $\phi$ is a representation shared by all environments, and $a$ is an environment-specific linear coefficient. We learn $\phi$ using meta-learning, and adapt $a$ using adaptive control. Namely, adaptive control will adapt $a_t$ in real-time based on the learned representation $\phi$. The reason behind is that adaptive control is super good at handling (linear) parametric uncertainty, so we use meta-learning to provide a reasonable representation to “translate” the nonparametric uncertainty to be parametric. See some theoretical analysis for Online Meta-Adaptive Control in our NeurIPS’21 paper.
Encoding invariance to deep learning really helps
The last principle I would like to share is the importance of encoding invariance to deep learning. Real-world autonomous systems have a lot of nice structures, which should be leveraged in deep learning. In Neural-Swarm, we encoded heterogeneous permutation invariance when learning the residual dynamics $g(x_t,u_t,N_1,\cdots,N_K)$. For example, $h(x_1,x_2,y_1,y_2)=\sin(x_1x_2)+\cos(y_1+y_2)$ is a heterogeneous-permutation-invariant function, because switching $x_1,x_2$ or $y_1,y_2$ doesn’t change the function output but switching $x_1,y_1$ does. It turns out that encoding such invariance is crucial and allows us to generalize from 1-3 robots in training to 5-16 robots in testing. The following video shows the data collection process, where we only used 1-3 robots:

|
Another type of invariance is domain invariance. Recall that in Neural-Fly we want to learn a representation $\phi$ that is shared by all environments. Therefore, we developed a domain adversarially invariant meta-learning algorithm to learn $\phi$ such that $\phi$ does not directly contain domain information. Interestingly, we found that standard meta-learning without such a domain invariance regularization tends to overfit, due to the underlying domain shift problem.
Aside: safe exploration in dynamical systems
In Neural-Lander/Swarm/Fly, we all need either a human expert or a well-tuned program under supervision for data collection. However, in many safety-critical tasks such as space exploration, there is no expert collecting data. Naturally, here comes a question: Can we safely collect data without humans in the loop, and eventually achieve an aggressive control goal? For example, landing the drone faster and faster. To address this challenge, we deployed distributionally robust learning together with optimal control. The key idea is that robust learning quantifies the uncertainty under domain shift, and optimal control ensures the worst-case safety. See more details in the deterministic and stochastic settings.
Closing Remarks
Neural-Control Family presents a class of deep-learning-based control methods for real-world systems with formal guarantees and new capabilities. Hopefully, I convinced you that there are three important principles:
- Having prior physics matters.
- Control meets learning: combining learning and control theory is necessary.
- Encoding invariance to deep learning really helps.
There are many interesting future directions. In particular, note that the aforementioned prior physics, invariance, and control-theoretic regularization are all directly from physics and relatively easy to discover. For more complex systems such as vision-based control and human-robot interaction, we need principled Neurosymbolic Learning methods to discover those structures from data.
References
- Neural-Lander [ICRA’19 paper]
- Neural-Swarm [T-RO paper]
- Neural-Fly [Science Robotics paper]
- Online Meta-Adaptive Control [NeurIPS’21 paper]
- Safe Exploration [L4DC’20 paper][RA-L paper]
Acknowledgements
Thanks to Prof. Yisong Yue for feedback on this post.